
Notes on Convex Optimization
by 장승환
In this page I summarize in a succinct and straighforward fashion what I learn from Convex Optimization course by Stephen Boyd, along with my own thoughts and related resources. I will update this page frequently, like every week, until it’s complete.
Acronyms
- LA: Linear Algebra
Preceding materials to be added..
(Lecture 9) Numerical linear algebra background
The main goal of the third and the last section (Lectures 9–12) of the course is to demystify how it is that we solve these convex optimization problems.
It is very important for everyone to know a little bit about how these problems are solved, and specifically the link between problem structure and how fast we can solve it.
Matrix structure and algorithm complexity
Cost of solving linear system $Ax = b$ ($A \in \mathbb{R}^{n\times n})$ :
- $n^3$, for general methods
- less, if $A$ is structured (banded, sparse, Toeplitz, etc)
FLOP counts
Linear equations that are easy to solve
- Diagonal : $n$ flops
- Lower triangular : $n^2$ flops via forward substitution
- Upper triangular : $n^2$ flops via backward substitution
- Orthogonal : $2n^n$ flops
- Permutation : $0$ flops
The factor-solve method for solving $Ax = b$
- Factor
- Solve
“Factorization dominates everything!”
$LU$ facorization (completely equivalent to Gaussian elimination)
Cholesky factorization
$LDL^{\rm T}$ factorization
Equations with structured sub-blocks
Structured matrix plus low rank term
(Lecture 10) Unconstrained minimization
Descent methods
Gradient descent
Steepest descent method
Newton’s method
Newton’s method by G. Strang
(ML 15.1) Newton’s method (for optimization) - intuition
(ML 15.2) Newton’s method (for optimization) in multiple dimensions
Newton step: $\Delta x_{\rm nt} = - \nabla f(x)^{-1}\nabla f(x)$
- $x + \Delta x_{\rm nt}$ minimizes 2nd order approximation (by a quadratic model):
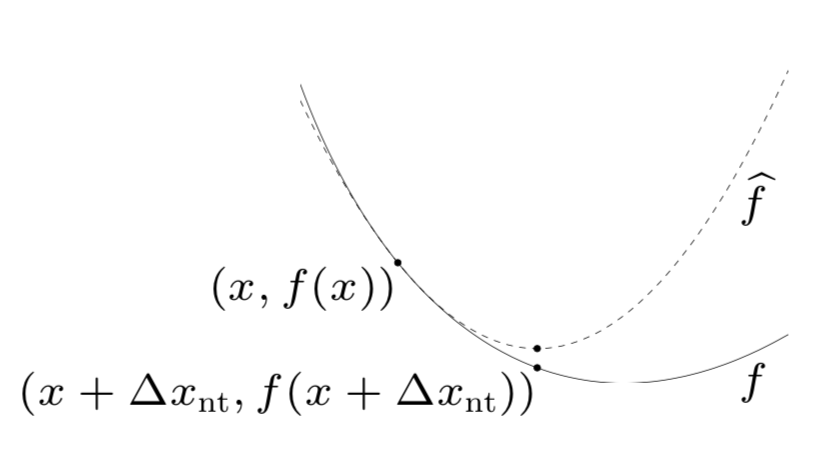
- $x + \Delta x_{\rm nt}$ solves linearized optimality condition:
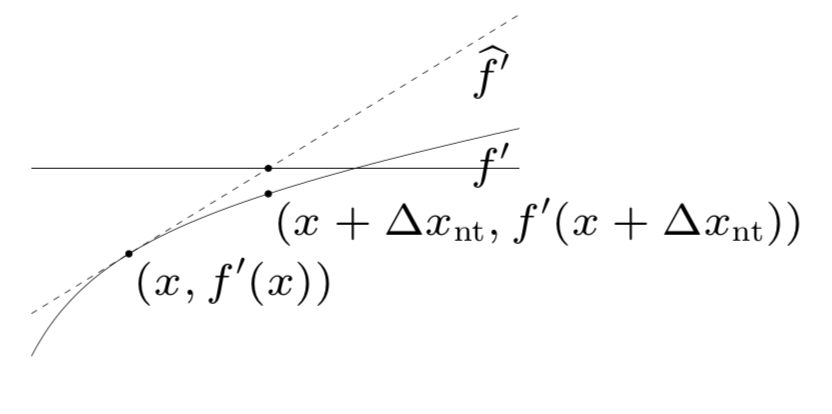
- $x + \Delta x_{\rm nt}$ is steeptest ditection at $x$ in local Hessian norm:
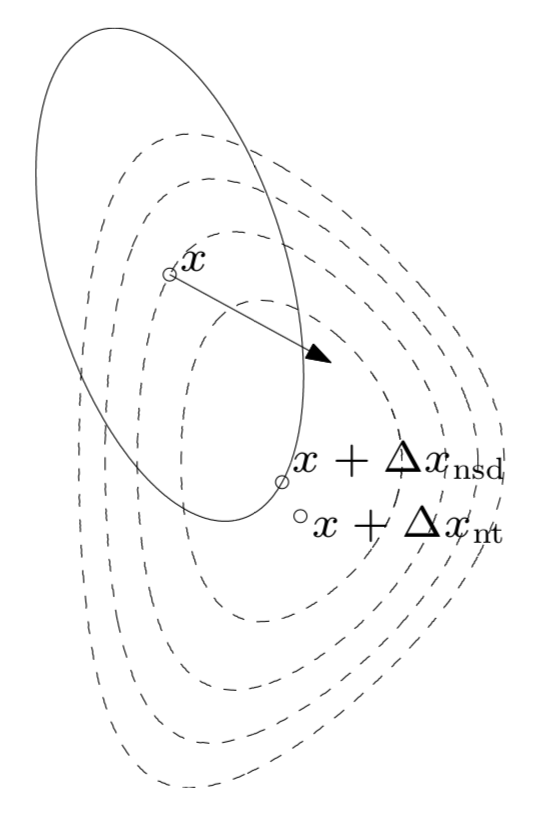
Newton decrement: a measure of the proximity of $x$ to $x^*$
- very good estimate, if you’re close, of $f(x) - p^*$ using quaratic approximation $\hat{f}$:
(provides way better stopping criteria than gradient!)
- equal to the norm of the Newton step in the quadratic Hessian form:
- directional derivative in the direction:
- affine invariant! (unlike the gradient $\Vert \nabla f(x) \Vert_2$)
Algorithm (Newton’s method)
given a starting point $x \in {\rm dom} (f)$ and tolerance $\epsilon >0$
repeat
$ \,\,\,\,\,\,\,\,$ 1. compute the Newton step and decrement:
$ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,$ $\Delta x_{\rm nt} = - \nabla f(x)^{-1}\nabla f(x)$
$ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,$ $\lambda(x) = (\nabla f(x)^T \nabla^2 f(x)^{-1} \nabla f(x))^{\frac{1}{2}}$
$ \,\,\,\,\,\,\,\,$ 2. stopping criterion: quit if $\lambda^2/2 \le \epsilon$
$ \,\,\,\,\,\,\,\,$ 3. line search: choose step size $t$ by backtracking line search
$ \,\,\,\,\,\,\,\,$ 4. update: $x \leftarrow x + t\Delta x_{\rm nt}$
To be added..
Subscribe via RSS